Building Experiment¶
After the problem has been created for optimization, we need to build an experiment configuration which includes the information required by optimization, for example, batch size, choice of algorithm, and so on. The experiment configuration can be either created through interactive GUI or loaded from a configuration file.
Creating Configuration through GUI¶
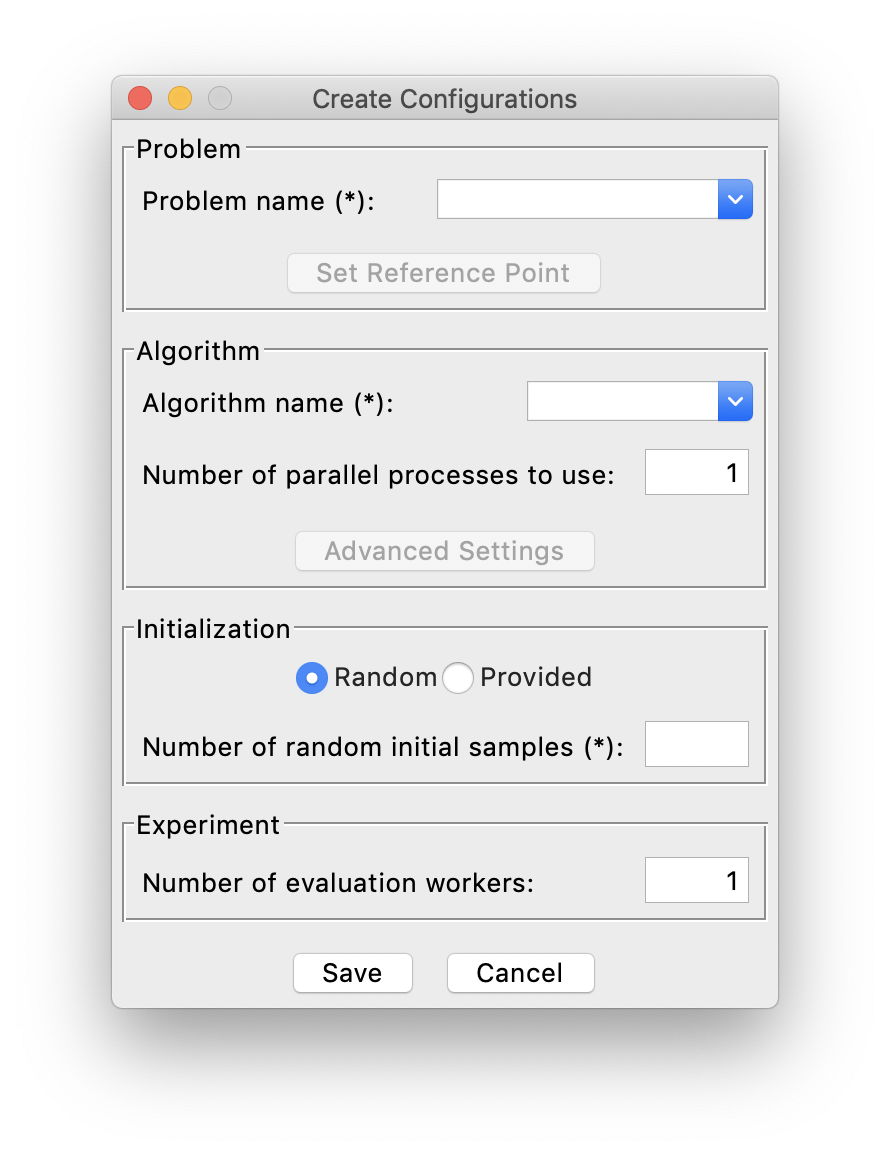
To build an experiment interactively through GUI, first click Config->Create from the menu, then this window will show:
Problem¶
First of all, you need to select which problem to optimize on the top, where you can see the whole list of created problems, along with many predefined test problems.
Algorithm¶
Next, we can select the specific algorithm to use for optimization. More detailed description of all the supported algorithms can be found in Supported Algorithms.
In general, although the performance of each algorithm varies greatly depending on the problem, we suggest using DGEMO
for most of the cases since it exhibits a relatively better and stabler performance. And you are also able to customize
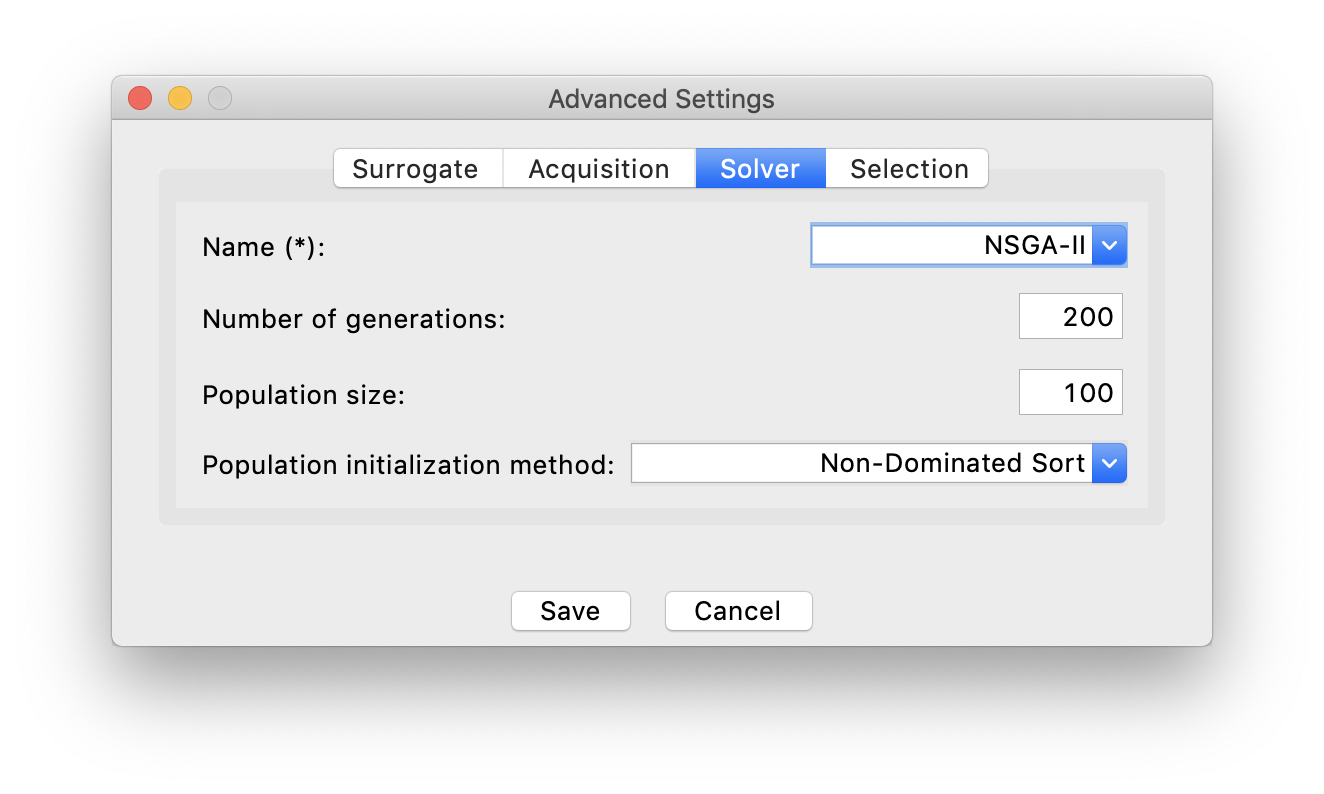
the parameters of the algorithms by clicking Advanced Settings, if you are not satisfied with the default choices. For example:
Initialization¶
Then, since the optimization rely on a set of initial samples (more than 1), you need to provide either: a number of initial samples that AutoOED will randomly generate for you, or the path to the file storing existing initial samples.
For initialization with random samples, make sure the Random choice is selected and you need to input the number of random initial
samples you want. For initialization with provided existing samples, the Provided choice has to be selected and you need to specify
the file location of existing samples by clicking the Browse buttons. For example:
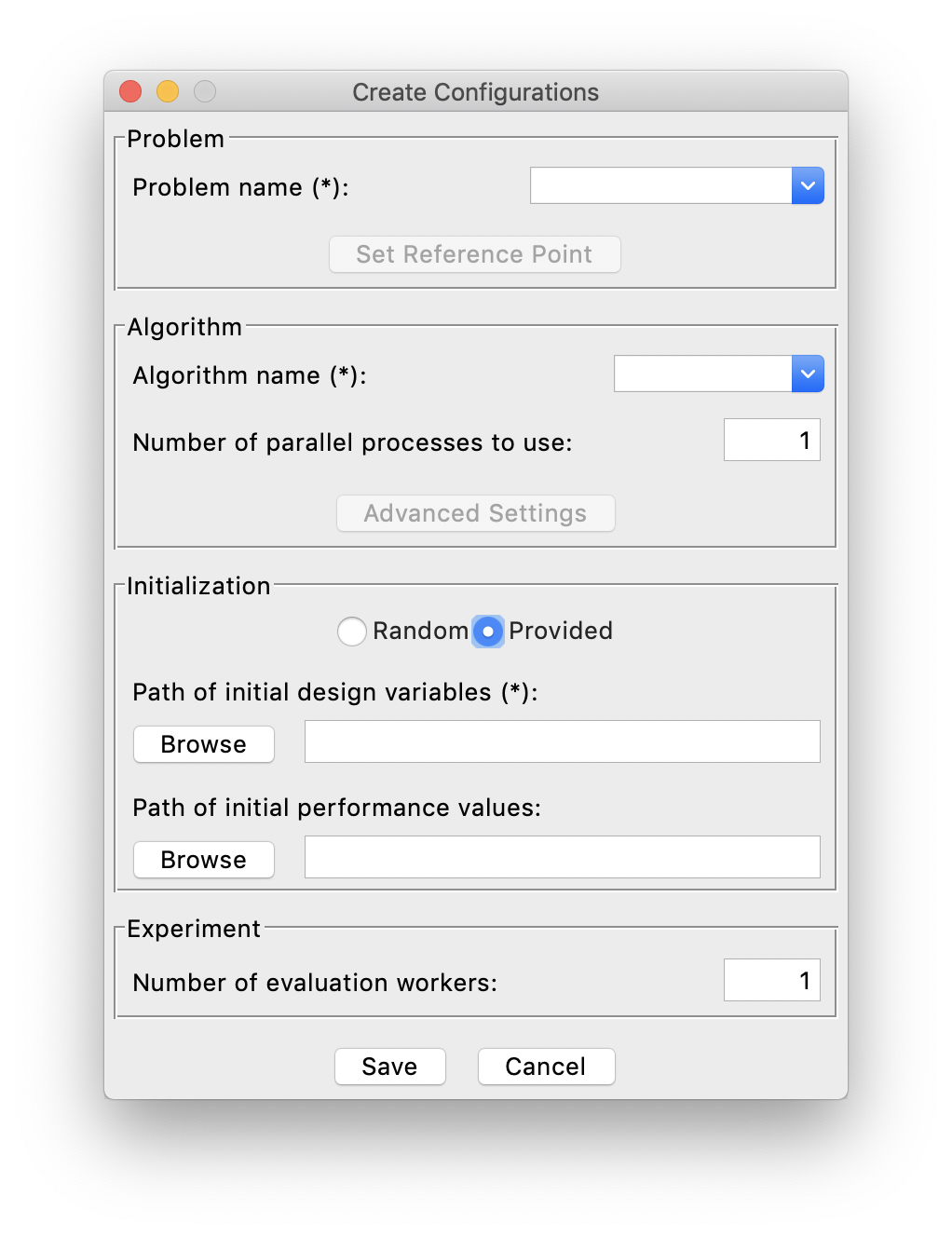
In this case, the initial design samples must be provided, either with or without corresponding initial performance values.
Experiment¶
Finally, you need to specify how many number of evaluation workers can be run in parallel. For example, if you only have one experimental setup that can only do one evaluation at a time, then the number of evaluation workers should be specified as 1. Otherwise, AutoOED will try to launch parallel evaluations with the maximum number of workers as you specified, when there are multiple design samples proposed by the algorithm to be evaluated.
Loading from Configuration File¶
To build an experiment from configuration file, first click Config->Load from the menu,
then a system window will pop up asking the location of the configuration file.
After loading the file, everything is done and you can start the optimization.
The configuration file should be in YAML format, and here we show how to compose a valid configuration file.
Configuration File¶
Overall, the configuration file should include three aspects: problem, algorithm and experiment.
problem:
# ...
algorithm:
# ...
experiment:
# ...
The simplest yet working configuration file should look like this:
problem:
name: # your problem name
algorithm:
name: # algorithm name
experiment:
n_random_sample: # number of initial random samples
n_worker: # number of evaluation workers that can be run in parallel
If you want more customization, for example, being able to specify reference point of the problem, setting detailed parameters of the algorithm, or initializing from provided samples, etc., then a more complicated configuration file could look like this:
problem:
name: # your problem name
algorithm:
name: # algorithm name
# NOTE: below are all optional settings for the algorithm
n_process: # number of parallel processes can be used for the algorithm
surrogate: # surrogate model settings
name: ...
nu: ...
acquisition: # acquisition function settings
name: ...
solver: # solver settings
name: ...
pop_size: ...
n_gen: ...
pop_init_method: ...
selection: # selection method settings
name: ...
experiment:
n_random_sample: # number of initial random samples
init_sample_path: # path to provided initial samples
# NOTE: at least one of n_random_sample and init_sample_path must be specified
n_worker: # number of evaluation workers that can be run in parallel